HARRY GARLAND

I work in the world of autonomous systems. My background is in reinforcement learning and cognitive neuroscience, and I've worked with Oxford (on RL alignment), and UCL (on RL explainability) prior to my current role at Embotech AG as a Forward-Deployed robotics engineer.
HARRYBGARLAND(AT)YAHOO(DOT)COM
VLA Models - A Promising Direction For Embodied AI
But What Is A VLA Model?
Vision-Language-Action (VLA) systems are designed to tie natural-language instructions to live visual observations and then turn that grounded understanding into motor commands. That multimodal grounding fills the gap that classic vision-only or reward-driven RL agents face: pure RL policies struggle to see what a user means and why an action matters, whereas VLAs have demonstrated higher versatility and generalisation across open-ended tasks in both simulation and the real world .At the pixel side of the pipeline, a modern image encoder—usually a Vision Transformer (ViT) or ConvNeXt—cuts an input frame into fixed 16 × 16 patches, flattens each patch, and projects it into a patch embedding, effectively treating every patch as a visual token just like words in NLP . These encoders come pre-trained on vast image or image-text corpora (ImageNet-22k, LAION-2B, DINOv2) so lower layers already recognise generic edges, textures and object parts before the robot sees a single demonstration . When a team already has a multimodal front-end—PaLM-E, BLIP-2 or the lightweight linear-projection scheme used in LLaVA—this entire visual branch can simply be inherited, bringing a pre-aligned vision-language space “for free” .Running in parallel, a language encoder tokenises incoming text with a sub-word scheme (Byte-Pair Encoding, SentencePiece, etc.), then maps each index to a dense vector. Maintaining the same hidden dimension d (often 768–2048) across vision and language means that a single linear layer can later mix the two streams without bespoke adapters—an architectural convenience that becomes crucial when scaling to billions of parameters . Functionally, aligning the dimensions allows the agent to ground phrases such as “pick up the red mug” in the very pixels where that mug appears.Those token streams meet inside a cross-modal fusion block. Three strategies dominate: FiLM layers that scale-and-shift vision features (used by RT-1), explicit cross-attention (favoured when parameter count is tight) and simple concatenation of all tokens into one big multimodal transformer (the default for large VLAs) . With cross-attention, a vision token corresponding to, say, patch 37 can query a language key storing the word “mug”, letting the network marry spatial and semantic cues in a single attention map. After several transformer layers the output is a set of fused embeddings that encode what is here and why it matters.To avoid treating each frame in isolation, many implementations append a lightweight world-state memory. Either a small key-value cache holds a few fused tokens from recent steps, or a dedicated state token is carried forward and updated at every pass. Both tricks give the policy short-horizon continuity without paying the full cost of a learned dynamics model—an idea that dovetails with the recent push toward transformer-based world models for longer-term planning .The fused observation is forwarded to the control stack. A near-term policy head outputs discrete logits (for binned joint poses) or continuous mean-variance pairs (for torque commands). Several groups now replace the traditional MLP or transformer decoder with a diffusion-based action head—Octo and MDT are prominent examples—because diffusion better captures multimodal trajectory distributions . An optional value head can be attached for reinforcement-learning fine-tuning. Crucially, if the upstream encoders remain unfrozen, gradients from the action loss flow back through fusion and perception, nudging visual and linguistic features toward action usefulness rather than static classification .Real-world tasks rarely finish in a single step, so most deployed agents wrap the low-level VLA in a hierarchical shell. A high-level planner—often an LLM guided by prompt-based affordance filters à la SayCan—decomposes a user goal into subtasks, while the VLA executes each subtask at ∼10–30 Hz. This separation lets the planner exploit large language capacity without burdening the latency-critical control loop .Training normally unfolds in three stages. First, the vision and language encoders are pre-trained or adopted from the foundation-model zoo. Next, the full stack is joint-trained on vision-language-action triples collected in simulation or from tele-operation logs, so that fusion learns true cross-modal grounding. Finally, the agent is fine-tuned with imitation learning, reinforcement learning, or reinforcement learning with human feedback (RL-HF) to respect task-specific rewards and safety constraints; discrete behaviour-cloning losses power most RT-series models, whereas diffusion-based VLAs minimise a denoising objective like L<sub>DDPM</sub> .Put together, a VLA agent consists of encoders that see and read, a fusion core that lets those interpretations cross-pollinate, and a control head that turns the blended representation into purposeful motion. The open research questions—robustness under domain shift, data-efficient grounding, transparent alignment of learned goals with human intent—lie not in any single component but in the delicate interactions among them.
My Theory of Change
This is admittedly a first for me. I've never thought this far forward about my work before but I think that's mainly because this is the first stage in my young research career that I've found a direction I feel I can contribute significant value towards and simultaneously gets me super excited. To be honest, I've always found "Theory of Change" (ToC) as a phrase to be a little cheesy but that's not to say I haven't understood its utility. As with most of my life (except perhaps certain purely creative arts) setting a clear direction and goal to work towards is an incredibly effective "rising tide" method. I think throughout the research experience I've gained I've learned a couple big-picture lessons: (1) It's incredibly easy to forget the bigger picture, (2) it's unfortunately easy to slow yourself down. A strong ToC therefore seems pretty important to maintain a drive towards a net goal and also maintain cognisant of your original intentions. The latter is an interesting one since this is not only a reference point to keep you on track but also one to (hopefully) prove your naivete towards the problem. You will be naturally wrong about many assumptions you make at the beginning of your research journey and it's important to reflect on why and how these assumptions are/were wrong and make informed steps from them based on your latest results. A research journey is a chain of experiments, best conducted alongside a passionate team, each experiment is a strong signal in a noisey ether and provides your next clues towards making the bigger picture of your research a reality.With all that in mind, I've attempted to cobble together my first ToC with respect to my latest research focus. I have become very interested in Vision-Language-Action (VLA) models (here's why) and I think they're likely to be the future of generalist autonomous systems. Nonetheless, VLA models inherit inscrutable black box transformer challenges and are likely to be deployed into safety-critical domains where they will interface with humans in an embodied form. Thus, they pose an additional physical misalignment risk, or rather a capable physical misalignment risk (one where they have sufficient coordination to achieve misaligned goals i.e. misalignment here doesn't look like "flailing limbs").It's crucial, therefore, for embodied VLA models to be able to respond well to human oversight in deployment, and possess some form of hierarchical coordination, and adaptive learning. Let's explore this more...
A Quick Summary of VLA Architecture
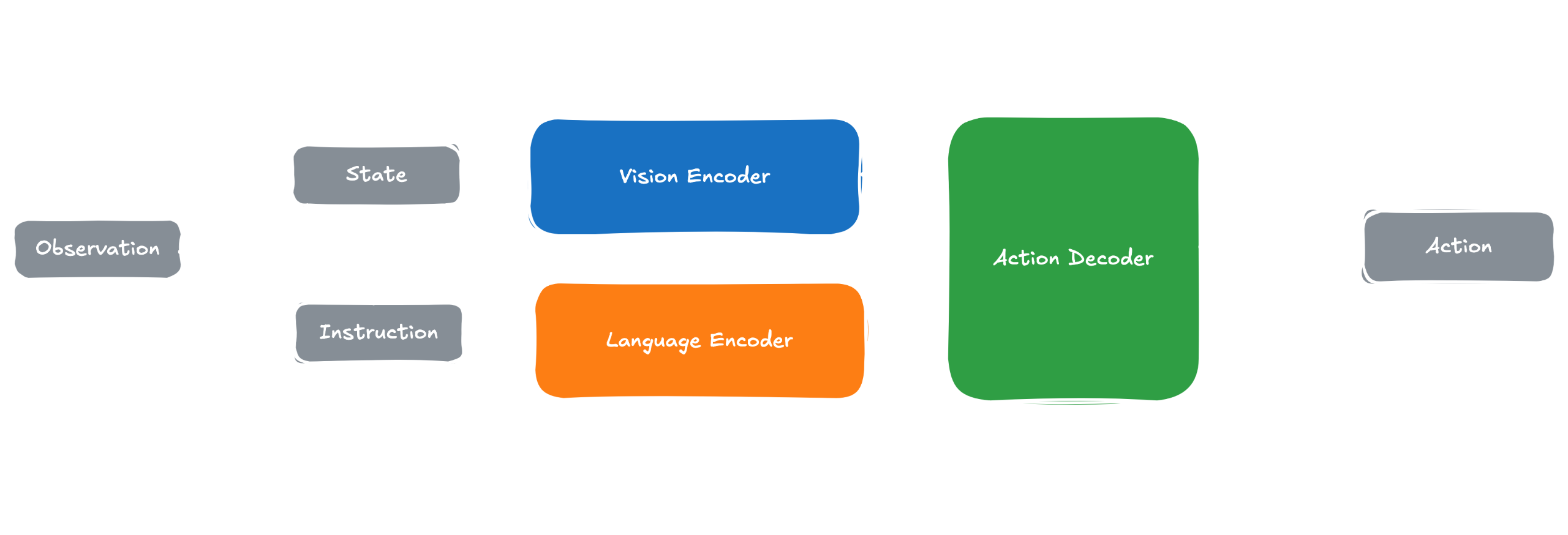
This is a high-level overview. For more information please read my detailed breakdown.Vision-Language-Action (VLA) models incorporate multimodal models to create better performing generalist policies for embodied agents that jointly perceive images, parse natural-language instructions and produce actions (continuous or discrete). The general structure looks as above, with a pre-trained vision/language backbone, such as a Vision Transformer converting each frame into patch embeddings, and a large language model encoding the instruction; both produce vectors in the same hidden dimension so that a fusion transformer - often implemented with FiLM scaling, cross-attention or simple token concatenation in larger systems - can align spatial pixels with linguistic semantics.The fused embeddings, optionally augmented with a lightweight key-value or state-token memory, are fed to an action decoder that predicts discrete or continuous actions, with gradients flowing end-to-end so perception is optimised for control rather than static recognition.VLAs start from internet-scale vision-language pre-training, are co-fine-tuned on robot demonstrations or simulation roll-outs, and then (optionally) refined with reinforcement learning or human-feedback objectives, yielding markedly stronger task generalisation than classic vision-only RL agents.Often, when deployed for long-horizon tasks they sit inside a hierarchical stack where a high-level planner decomposes goals into subtasks that the VLA controller executes in real time, marrying language reasoning capacity with low-latency motor control.
The Transparency Gap: Human Cognition & VLA Alignment
To understand what's missing in current VLA architectures, I want to first examine how biological systems solve the coordination problem. Human cognitive-motor function is organised around a shared neural code that links perception, deliberative reasoning, and action. At the behavioural level this principle appears in ideomotor or common-coding theory: perceptual events and intended actions are represented in the same format, so that activating one automatically primes the other. Neurophysiology supplies a somatotopic illustration: hearing verbs like "kick" triggers leg-motor cortex with initial activation as early as 150ms and peak effects around 200ms, though semantic integration continues for several hundred milliseconds. Perturbing motor areas with TMS slows lexical decisions on the same words, though effects depend critically on stimulation timing and individual differences in sensorimotor grounding strength.These bidirectional links are sustained by efference-copy circuits that forward every outgoing motor command to sensory regions, allowing fast prediction–error corrections and a single, continuously updated estimate of "what we're trying to do." However, maintaining these parallel monitoring systems incurs significant metabolic costs, leading the brain to selectively engage or bypass emulator mechanisms depending on task demands and contextual precision requirements.Complementing these loops is an internal emulator—a forward model that runs in parallel with the body and environment. The emulator predicts forthcoming sensory states fast enough to guide action on the next timestep and can even be run off-line for mental imagery and counterfactual planning. Together, the common code and the emulator give higher cortical planners direct read-and-write access to the same variables that drive the motor periphery, closing the cognitive–motor gap that hierarchical AI stacks often leave open.Importantly, critiques of strong embodiment show that the motor trace is supportive but not sufficient: abstract goals remain symbolic, yet they stay aligned because they are continuously instantiated in—and checked against—sensorimotor circuits. This framework works robustly for action- and spatially-related cognition, but its extension to highly abstract domains like mathematical reasoning or complex social cognition remains more contentious. Recent evidence suggests that apparent sensorimotor activation during abstract thinking may sometimes reflect post-hoc simulation—the motor system "filling in" details after comprehension—rather than constitutive processing driving understanding.Developmental considerations reveal that this integrated architecture emerges gradually. Infants initially show very different coupling patterns between perception and action, with the mature bidirectional links developing through extended sensorimotor experience and cortical myelination. This suggests the common code is constructed rather than innate, with important implications for understanding individual differences in embodied cognition.Under this integrated architecture, planning areas (pre-frontal cortex, basal ganglia) compute priorities and select goals, parietal and premotor regions encode those goals in a sensorimotor format, and primary motor cortex translates the same code into muscle torques—all while incoming sensory signals are compared, millisecond by millisecond, with emulator predictions. Errors that slip through re-enter the loop as prediction mismatches, updating both belief and motor output in one pass. The upshot is a transparent, persistent goal representation accessible at every level of the hierarchy: perception knows why it is sampling, reasoning knows what the body can do next, and action execution can be revised mid-stream without losing sight of the overarching objective.The VLA Coordination ProblemThis biological architecture highlights exactly what's missing in current VLA systems. The precise needle I believe we're failing to thread involves several interconnected issues that distinguish artificial from biological coordination.Closed-loop control already exists in VLA systems. A VLA policy receives a fresh camera frame every few hundred milliseconds, issues an action, and the cycle repeats. In that sense perception and control are "co-ordinated"—the actioner always works on up-to-date state. Yet coordination does not equal shared, transparent understanding. The perceptor hands the actioner a latent vector whose inner meaning no one has decoded; the actioner replies with torques whose rationale is equally opaque. We assume those latents still encode the high-level goal the reasoner issued, yet we cannot inspect or prove that alignment.The opacity problem multiplies in hierarchical stacks. When a higher-level planner feeds sub-goals to the VLA, we introduce an extra interface whose fidelity is also unverified. Now two black-box boundaries—planner to VLA, and perceptor to actioner—must both preserve the same goal semantics without any shared, checkable representation. This is what fundamentally differs from the human case. In the brain, planning, perception, and motor areas all read and write a live, distributed goal code; if a movement starts to drift, the same neurons that encode the plan help correct it. VLAs do have sensory feedback, but the meaning of the goal is not carried across modules in a form we can interrogate. We only see embeddings going in and torques coming out—and no guarantee that they still point at the same objective.My pinpointed concern is not the absence of a feedback loop, but the absence of a transparent, persistent representation of the goal that every module—plus any human or supervisory AI—can inspect, verify, and, if necessary, override. Until such a representation exists, we cannot be sure that the perceptor's embeddings, the actioner's policy, and the planner's instructions are genuinely talking about the same thing, even though the control loop is technically closed.This transparency gap represents both the core safety challenge and the key research opportunity in VLA alignment. The question becomes: can we engineer something analogous to the brain's shared neural code into our artificial systems?
My Proposed Approach: Mechanistic Interpretability for VLA Models
Given this transparency gap, my research focuses on developing mechanistic interpretability techniques specifically designed to understand and engineer goal alignment in VLA architectures. My theory of change operates on three interconnected phases, each building toward deployment-ready oversight systems for embodied AI.Near-term (1-2 years): Decoding VLA Goal RepresentationsThe foundation of my approach involves adapting existing mechanistic interpretability techniques to understand how VLAs internally represent and process goals. This phase leverages several established methods, modified for the unique challenges of multimodal robotic systems.Sparse Autoencoders for Goal Feature Discovery: I'll train SAEs on VLA fusion layers—the critical juncture where vision and language representations merge—to identify sparse, interpretable features that correspond to goal components. Unlike traditional language models where SAEs typically target MLP layers, VLAs require focus on cross-attention mechanisms where multimodal interaction actually occurs. This should reveal how goal information is structured in the joint embedding space and whether semantic goal components remain disentangled or become entangled during fusion.Goal-Aware Probing Techniques: Traditional probing methods need adaptation for the multimodal context of VLAs. I'll develop probing protocols that test for preservation of instruction semantics across the perception-action pipeline, specifically targeting the fusion layer where linguistic goals must be grounded in visual context. This involves creating probe datasets that systematically vary goal complexity, specificity, and abstraction level to understand the limits of VLA goal representation.Modified Activation Patching for Causal Tracing: Standard activation patching techniques assume single-modality processing, but VLAs require interventions that respect cross-modal dependencies. I'll develop semantically meaningful intervention protocols—rather than Gaussian noise—that correspond to specific goal modifications. This means patching between instruction encoding and action generation to trace causal pathways, and intervening at vision-language fusion points to test goal preservation under visual context changes.Cross-Modal Attention Analysis: Since VLAs fundamentally depend on cross-attention between vision and language modalities, I'll leverage attention visualization to trace how linguistic goal specifications attend to relevant visual features throughout processing. This should reveal whether attention patterns remain stable across similar goals and how visual context modulates goal interpretation.Logit Lens Adaptation for Action Space: By projecting intermediate VLA representations back to action space rather than vocabulary space, I can observe how goal representations evolve through the network toward action generation. This technique should reveal at what processing stage goal information becomes action-specific and whether high-level intentions remain accessible in later layers.My near-term research plan proceeds in three phases. First, I'll apply SAEs to popular VLA architectures like OpenVLA and RT-2 to identify interpretable features in fusion layers, while developing goal-aware probing techniques and creating modified activation patching protocols. Second, I'll use attention analysis combined with activation patching to trace goal information flow from instruction through fusion to action, developing "goal consistency" metrics that measure alignment between instruction encoding and action generation. Third, I'll integrate insights from multiple techniques to create comprehensive "goal maps" of VLA processing and begin developing real-time goal monitoring tools.Medium-term (2-4 years): Engineering Transparent Goal RepresentationsBuilding on interpretability insights, this phase focuses on developing training techniques and architectural modifications that encourage VLAs to maintain explicit, interpretable goal representations throughout their processing pipeline.Architecture-Guided Transparency: Using findings from the interpretability phase, I'll experiment with architectural modifications that preserve goal information in human-readable formats. This could involve introducing explicit goal bottlenecks in the fusion layer, designing attention mechanisms that maintain goal-visual correspondence, or implementing parallel goal-tracking pathways that run alongside standard processing.Training Objectives for Goal Alignment: I'll develop training objectives that reward goal-state alignment across modules, ensuring that goal representations remain consistent from instruction encoding through action generation. This involves creating auxiliary loss functions that penalize goal drift, reward goal preservation under visual perturbations, and encourage disentangled goal representation in the embedding space.Intervention Frameworks: Based on causal understanding from the interpretability phase, I'll develop intervention techniques that allow real-time goal verification and correction during VLA processing. This means creating protocols for surgical goal modification without disrupting overall network function.Long-term (4-8 years): Deployment-Ready Oversight SystemsThe ultimate objective is creating VLA systems where human operators can inspect, verify, and if necessary override the AI's understanding of its objectives in real-time, enabling safe human-AI collaboration in physical environments.Human-Accessible Goal Interfaces: I'll develop interfaces that make goal representations accessible to non-technical users, translating technical interpretability insights into intuitive oversight tools. This involves creating visualization systems that show goal evolution during task execution and alert systems that flag potential goal misalignment.Automated Goal Monitoring: Building on the interpretability and intervention frameworks, I'll create automated monitoring systems that flag goal drift before it manifests in physical actions. These systems would run in parallel with VLA processing, continuously checking goal consistency and triggering alerts when interventions might be necessary.Safe Collaboration Protocols: Finally, I'll establish protocols for safe human-AI collaboration in physical environments, where humans can seamlessly intervene in VLA goal processing without disrupting task execution or creating safety hazards.
Why This Matters
This research trajectory addresses a fundamental gap in current AI alignment work. While most interpretability research focuses on language models in purely digital environments, VLAs represent the first wave of AI systems that will operate autonomously in physical spaces. The stakes are inherently higher—goal misalignment doesn't just mean incorrect text generation, but potentially dangerous physical actions.Moreover, VLAs are still in their architectural infancy, meaning interpretability insights can influence their development toward more transparent designs rather than requiring post-hoc analysis of entrenched black boxes. By establishing interpretability foundations now, we can guide the field toward inherently more alignable architectures before deployment pressures lock in opaque designs.The approach also bridges two critical gaps in current alignment research: the interpretability-control gap (moving from understanding to intervention) and the research-deployment gap (creating tools that work in real operational environments). Success here would establish a template for interpretable embodied AI that extends beyond robotics to autonomous vehicles, medical devices, and other safety-critical physical AI systems.
Key Uncertainties
If I'm being honest with myself, there are significant uncertainties baked into this theory of change that I need to acknowledge. As I mentioned earlier, one of the most valuable aspects of articulating a clear research direction is creating a reference point to measure your evolving understanding against. So let me be transparent about where I think my current assumptions might prove naive.Technical UncertaintiesWill existing mechanistic interpretability techniques actually transfer meaningfully to VLAs? My entire near-term plan assumes that SAEs, activation patching, and probing will work on multimodal fusion layers in ways that produce coherent insights. But VLAs might process information in fundamentally different ways than language models. The cross-modal interactions could be too complex or distributed for current interpretability tools to capture anything meaningful. I'm betting on transferability, but I honestly don't know if the techniques that work for GPT-style models will tell us anything useful about vision-language-action systems.Does goal information actually persist in interpretable forms throughout VLA processing? I'm assuming that VLAs maintain some recoverable representation of goals as they move from instruction encoding through fusion to action generation. But they might immediately transform linguistic instructions into purely procedural or motor representations that bear no resemblance to the original semantic content. The "goal" I'm trying to track might only exist fleetingly at the input stage, disappearing into distributed motor patterns that are inherently uninterpretable in linguistic terms.Can I engineer transparency without fundamentally breaking what makes VLAs work? My medium-term phase assumes I can modify architectures and training objectives to maintain transparent goal representations without sacrificing performance. But the opacity might be a feature, not a bug. The very thing that makes VLAs effective—their ability to seamlessly integrate multimodal information into fluid action—might depend on representations that resist human interpretation. Forcing transparency could break the capabilities I'm trying to make safer.Scaling and Generalization UncertaintiesWill my insights from today's VLAs apply to tomorrow's architectures? I'm planning to study current designs like RT-2 and OpenVLA, but this field is moving incredibly fast. The architectural innovations happening in the next few years could make my interpretability techniques completely obsolete before I even finish developing them. I'm essentially betting that the core principles of vision-language-action integration will remain stable enough for my work to stay relevant.Do different domains require completely different interpretability approaches? VLAs for household robots might process goals very differently than those designed for manufacturing, autonomous vehicles, or medical applications. My approach might only work for narrow task domains, requiring me to essentially restart the interpretability work for each new application area. The generalizability I'm assuming might not exist.Can interpretability techniques keep pace with capability scaling? As VLAs become more capable and their internal representations more complex, my interpretability methods might hit fundamental limits. I'm working under the assumption that interpretability can scale alongside capability, but there might be an inherent trade-off where sufficiently capable systems become inherently uninterpretable, regardless of the techniques I develop.Deployment and Impact UncertaintiesWill anyone actually choose to deploy interpretable VLA systems? Even if I succeed technically, the deployment incentives might strongly favor black-box systems that simply perform better. My interpretable systems might get relegated to low-stakes applications where transparency isn't actually crucial—essentially solving the safety problem for contexts where it doesn't matter much.Are humans actually capable of meaningful VLA oversight? My long-term vision assumes humans can effectively interpret and intervene in goal representations during real-time operation. But the cognitive load might be too high for practical oversight. The "human-accessible interfaces" I'm imagining might work in controlled laboratory settings but prove useless when a robot is operating in a complex, dynamic environment where split-second decisions matter.Am I focusing on the right level of intervention? I'm concentrating on goal-level interpretability, but maybe the real safety issues occur at different levels—in low-level motor control, sensory processing, or high-level task decomposition and environment modeling. I might be optimizing for transparency in exactly the wrong part of the system.Strategic UncertaintiesAm I solving yesterday's problem? By the time I develop mature interpretability techniques for VLAs, the field might have moved to fundamentally different alignment approaches. Constitutional AI, formal verification, or entirely new safety paradigms could make my interpretability work irrelevant. I'm betting that interpretability will remain a central approach to AI safety, but that's far from guaranteed.Will the research community value this work? I'm operating at the intersection of mechanistic interpretability (currently focused on language models) and robotics research (traditionally emphasizing performance over interpretability). Both communities might view my work as interesting but not central to their core concerns. I could end up with research that falls between stools rather than bridging important gaps.How I Plan to Navigate These UncertaintiesThese uncertainties don't paralyze me—they clarify where I need to build in flexibility and maintain intellectual humility. My research plan includes several hedge strategies: I'm designing experiments that can pivot if initial assumptions prove wrong, maintaining connections across multiple research communities to stay aware of shifting priorities, and focusing on developing transferable insights rather than technique-specific implementations.Most importantly, I'm committed to updating this theory of change as I learn more. The assumptions I'm making today will undoubtedly prove partially wrong, and the mark of successful research will be how intelligently I adapt when that happens. The goal isn't to be right about everything upfront—it's to make progress on important problems while remaining responsive to new evidence about what approaches actually work.This uncertainty is also why I find this research direction genuinely exciting. If the path forward were obvious, it wouldn't be worth pursuing. The fact that I'm working on problems where the solutions aren't predetermined means there's real potential for fundamental contributions to how we understand and control AI systems in physical environments.
Addressing Misalignment In Search & Rescue Robots
Estimated Read Time: 23 minutes
Reinforcement learning (RL) is a powerful machine learning technique in which an agent learns to make decisions by interacting with its environment in order to maximise some notion of cumulative reward. It is the job of the engineer to design these rewards in a way that causes the agent to learn a behaviour policy that achieves a specific goal. However, this technique has an interesting limitation which can lead to peculiar outcomes. When training an agent, we cannot simply tell it the goal we want it to learn; we must guide its behaviour towards this goal using rewards. It's therefore possible for the agent to learn a behaviour policy that appears to be aligned with our goal, but in actuality, when deployed, does something completely different, demonstrating misalignment (see this spreadsheet for a long list of examples). There are many possible causes of misalignment. It might arise from issues during the training phase, or perhaps particular differences between the training and deployment environments. Today, we will be taking a closer look at one particular instance of misalignment in RL: sparse reward deployment environments with novel obstacles for single life reinforcement learning (SLRL) scenarios such as search and rescue robots.Ooof, that's a bit of a mouthful! So, before we move ahead, let's break it down. As previously mentioned, when we train an agent to complete a goal we do so by supplying it with rewards that guide its behaviour towards that goal. For example, we might be training a search and rescue robot dog (Rex) to locate a human in a building, so (using a simulation for efficiency) we'd create a bunch of random building interiors, deploy Rex into this environment, and let it explore. We'd "feed" Rex rewards only when it locates the human, and offer it nothing otherwise. Over time we update Rex's behaviour policy to increase the probability of making decisions that lead to the reward, and decrease the probability of making decisions that don't. Well, it's not actually us who updates the behaviour policy, but a particular class of deep RL algorithms known as 'policy gradient methods', e.g. proximal policy optimisation. Eventually, this process causes Rex to learn an efficient behaviour policy for search and rescue environments.So, why might it all go wrong on deployment? Well, search and rescue is a particular case of SLRL, which itself is any instance where, an agent, having learned a particular behaviour policy in one environment, is placed into a new environment with novel obstacles. The agent must use its prior experience (learned policy) to navigate this new environment and novel obstacles in a single attempt, without any human (or other) interventions. Put more directly, when we throw Rex into a burning building and say, "now go find the human!" it's likely to come across obstacles (such as fallen debris or fires) in novel and unpredictable ways. On top of that, Rex can't be overseen by a human, it must act autonomously and also cannot be picked up and reset if it goes wrong. Rex has one chance to efficiently locate the human or we're out of luck! So why do these novel obstacles cause such a problem? Why can't we just train Rex to deal with them before deployment? Well, whilst you and I might be able to list dozens (or more) possible novel obstacles Rex could encounter, the point of SLRL is, that these deployment environments are inherently, dynamic, unstable and unpredictable. There's always a chance that Rex encounters something we haven't thought of, or perhaps something we have thought of but in a completely new way (think fallen debris on fire, that's rolling down the stairs!). Further, because of the nature of the problem Rex is tackling, we have had to define its training reward signal in such a way that allows it to learn a sufficiently generalisable search and rescue policy. This means, we've had to keep the reward signal quite sparse (i.e. only offering a reward when Rex finds the human). Whilst necessary, this causes problems in deployment because Rex does not directly learn the goal of search and rescue, it instead learns a particular behaviour policy that allows it to complete the goal of search and rescue. This is a subtle but important distinction because, in deployment Rex will follow this behaviour policy to navigate the building and attempt to complete its mission. However, upon encountering a novel obstacle, Rex has to update its behaviour policy to allow it to adapt and navigate around this obstacle. In doing so it partially overwrites what it learned in its training and therefore, in successfully adapting to and navigating around the novel obstacle it loses sight of its original behaviour policy. This also means it loses sight of its original goal of search and rescue too.This is both the beauty and curse of RL. These algorithms are incredibly sophisticated and adaptable, but they weren't built for such SLRL scenarios with sparse reward signals and thus demonstrate incredible fragility when faced with novel obstacles that cause them to move "off-distribution".In the text that follows, we're going to dive into this problem in more detail, but don't worry, I'll keep us at a relatively comfortable cruising altitude when it comes to all the technical stuff. We'll explore a sophisticated and powerful technique to combat SLRL misalignment, known as "Q-Weighted Adversarial Learning" (QWALE) and then think about how we might take inspiration from Prof. Feldman Barrett's theory of Constructed Emotion to introduce "affect-inspired" enhancements to QWALE and potentially make it even better!
(Note: If you're feeling a bit lost by what you read above, don't worry this machine learning stuff can get a bit confusing! I'll be doing my best to not dive too deeply into any of the hairy stuff throughout this article, so my hope is that you can still walk away with a decent intuition about the problem at hand and the possible approaches to tackling it. Nonetheless, I do suggest clicking on any (and all) of the hyperlinks provided throughout the text, they're there to help fill in possible gaps where it would take me too much room to do so here)
Q-Weighted Adversarial Learning
QWALE builds on an algorithm called Generative Adversarial Imitation Learning (GAIL) to develop a sophisticated and powerful way of correcting the divergence of behaviour caused by novel obstacles in SLRL scenarios. As mentioned in the introduction, when we teach a robot like Rex the goal of search and rescue, we do so by way of guiding it with rewards. These rewards cause Rex to learn a particular behaviour policy which in turn causes it to increase the probability of making decisions that lead to achieving a reward (finding our human) more likely and decrease the likelihood of making decisions that don't. You can think of this like developing a particular propensity to behave in a manner that both efficiently navigates and explores each building's internal layout to maximally increase the chance of receiving a reward (finding our human). For example, instead of wandering around the corridors, Rex might learn to check each room it passes.After sufficient training, once we're happy with Rex's behaviour (we can see that, on average it is receiving rewards in an efficient manner) we can say that Rex has settled on a particular behaviour policy distribution. I.e. on average Rex will make particular decisions (choose particular actions) in response to particular observations about the world it's in (states). As a result, we can actually train a separate deep neural network to detect, with a high level of accuracy whether Rex is making decisions based on its learned behaviour policy or some other random one. We call this the discriminator network.So, why does this matter? Well, remember how we mentioned that novel obstacles cause Rex to overwrite its previous behaviour policy and begin making "off-distribution" actions that cause it to diverge from the overall goal of search and rescue? This discriminator network allows us to detect when that's happening and correct the behaviour back towards the original policy.Let's explore that in a bit more detail...So, let's say Rex has learned to explore each room along a corridor before moving on to the next floor. It's learned to do this in training by, at first, making random decisions (sometimes go past rooms, sometimes go into rooms) and learning over time that, on average, when it checks each room (instead of walking past them) it increases its probability of receiving a reward (finding the human) more quickly. Now, Rex doesn't keep a long list of to-dos that it references each time we place it into a new environment (e.g. do: check each room, don't: walk past rooms). Rex learns an incredibly vast amount of sophisticated behaviour in training, far too much to be reasonably captured using a list! So, in order to encode its behaviour policy effectively it uses the power of deep neural networks. Don't worry, we won't go too "deep" into that all here (although, I recommend this video for a great introduction) but at a very high level, you should understand the following. The neural network(s) powering Rex's decision-making essentially encodes, in response to a certain sequence of images from Rex's RGB camera, what actions it should choose that will increase its likelihood of receiving rewards the quickest, on average. It's able to encode this using a finite (but incredibly large) set of "neurons" which, when adjusted, over time, suppress the probability of actions which don't lead efficiently to rewards and increase the probability of actions that do. It's important to stress here that (at a high level) this large set of neurons eventually converge to one particular "configuration" that encodes all of this behaviour. At this point, when given any sequence of images from the possible observations Rex might make, the behaviour policy network will be able to output the optimal actions to take. This final distribution of average optimal actions in response to states (image sequences) we refer to as the learned behaviour policy distribution of Rex's policy network (deep neural network controlling the decisions). This particular configuration post-training encodes within it all of Rex's knowledge and importantly its overall goal of search and rescue.When we deploy Rex in SLRL scenarios, it will be acting autonomously with no human oversight or redos. Therefore, we have to allow for its neural network to continue updating itself (i.e. learning), because, if it encounters a novel obstacle such as debris it needs to figure out a way around it, which is not something that will be encoded in its learned knowledge (because these obstacles are novel). More directly, the behaviour policy neural network (for the sake of this example) will not have processed a sequence of RGB images with "debris" in before. So, it won't have encoded the optimal actions to select in response to this observation. In following its learnt behaviour policy distribution from training it might begin by walking straight into the debris and getting stuck. After not being able to move for a while, it will begin to realise it's now no longer selecting actions which lead it to its reward in the most optimal way (because it's not moving). So, it will begin to update the internal configuration of neurons in such a way that - for this ongoing sequence of "debris" images in-view - suppress the probability of re-selecting the sub-optimal actions it currently chooses (i.e. walk through the debris) and increase the probability of selecting other more optimal actions (i.e. walk around the debris). However, by changing the internal configuration of neurons it has now affected the behaviour policy this neural network encodes, thus affecting the way it responds to all future image sequences. In this way it has overwritten certain aspects of its original knowledge and can (and often does) lose sight of its original goal of search and rescue as a consequence. We call this, getting stuck "off-distribution".This is the important point to understand. We must allow Rex (and by extension Rex's behaviour policy) to adapt to these novel obstacles (which we cannot train it for) but in doing so we allow it to overwrite its previously learned knowledge, causing sub-optimal future decisions in response to image sequences it continues to process after successfully navigating around a novel obstacle. This causes it to fall into further sub-optimal corrections and ultimately end up completely "off-distribution", losing sight of its original search and rescue goals. A very costly problem!In the video below you can see a simple example of such SLRL misalignment occuring in real time. For a "two-legged cheetah" which was successfully trained to walk across a flat surface towards a finish line in an environment with no obstacles (hurdles), when it is placed into an environment with hurdles, we witness it fall off-distribution and become misaligned. In a similar way to that explained above, the cheetah begins to dynamically update its policy (the internal "configuration" of neurons in its neural network) in order to get over the first hurdle, but in doing so it overwrites the knowledge it previously learned of "how to walk" and thus gets stuck on its back lacking any ability to recover and losing sight of its overall goal to cross the finish line.
Great. Now that we (hopefully) understand more clearly how this problem occurs let's revisit the discriminator network we spoke about earlier that QWALE uses as its "secret sauce" to correct this problem. As a reminder, the discriminator network, upon viewing a given state (sequence of images) and chosen action (decision made in response) by a particular policy network, is able to determine with high accuracy whether these decisions were made by the policy network Rex developed in training (i.e. the one that encodes optimal search and rescue knowledge) or some other random policy network. Which is useful because, when we deploy Rex into the real world, we can deploy it alongside this discriminator network such that for every action Rex's policy network chooses in response to a given sequence of images, we give this information to the discriminator network and get it to produce an "error signal" in response. This just means we get it to tell us whether these actions selected in response to these images were made by something akin to the original learned behaviour policy or not. Eventually, when Rex encounters a novel obstacle like in the debris example, and starts to change its behaviour, this discriminator network is going to notice and begin producing a stronger error signal i.e. tell us loud and clear that Rex's policy network is moving "off-distribution". We can then use this error signal to penalise Rex's behaviour policy for being off-distribution. This forces it to begin choosing actions which minimise being penalised (receiving negative rewards) - remember, the goal of Rex’s behaviour policy network is to maximise expected rewards over time. The clever part is, the discriminator network only penalises Rex for choosing actions which are significantly different to its originally learned behaviour policy and therefore, when Rex attempts to reduce negative reward over time, it also realigns back towards its originally learned behaviour policy distribution, thus, reinstating its knowledge of search and rescue.The important bit about QWALE (that differentiates it from other SLRL realignment methods like GAIL) is that the error signal the discriminator network produces is "Q-weighted". This means it guides Rex towards states in the original behaviour policy distribution that are most valuable. Intuitively, these are states which are closer in proximity to the reward. Since, in training, Rex only received rewards for completing the mission (finding the human), QWALE essentially "pulls" Rex's off-distribution, adapting policy, towards states on-distribution that are closest to our main objective for Rex (find the human). This enhances the quality of realignment towards states most relevant for mission success in our SLRL search and rescue scenario.In the video below, you can see what happens when we apply QWALE to that same "two-legged cheetah" scenario. The cheetah encounters the first hurdle, adapts its originally learned "walking" policy in order to get over it and then, instead of getting stuck off-distribution, uses the error signal produced by the discriminator network to move its behaviour policy back towards its originally learned distribution (encoding how to walk) and thus, gets back on its feet and continues to the second hurdle. Here, it repeats the same process and eventually achieves its ultimate goal of crossing the finish line.
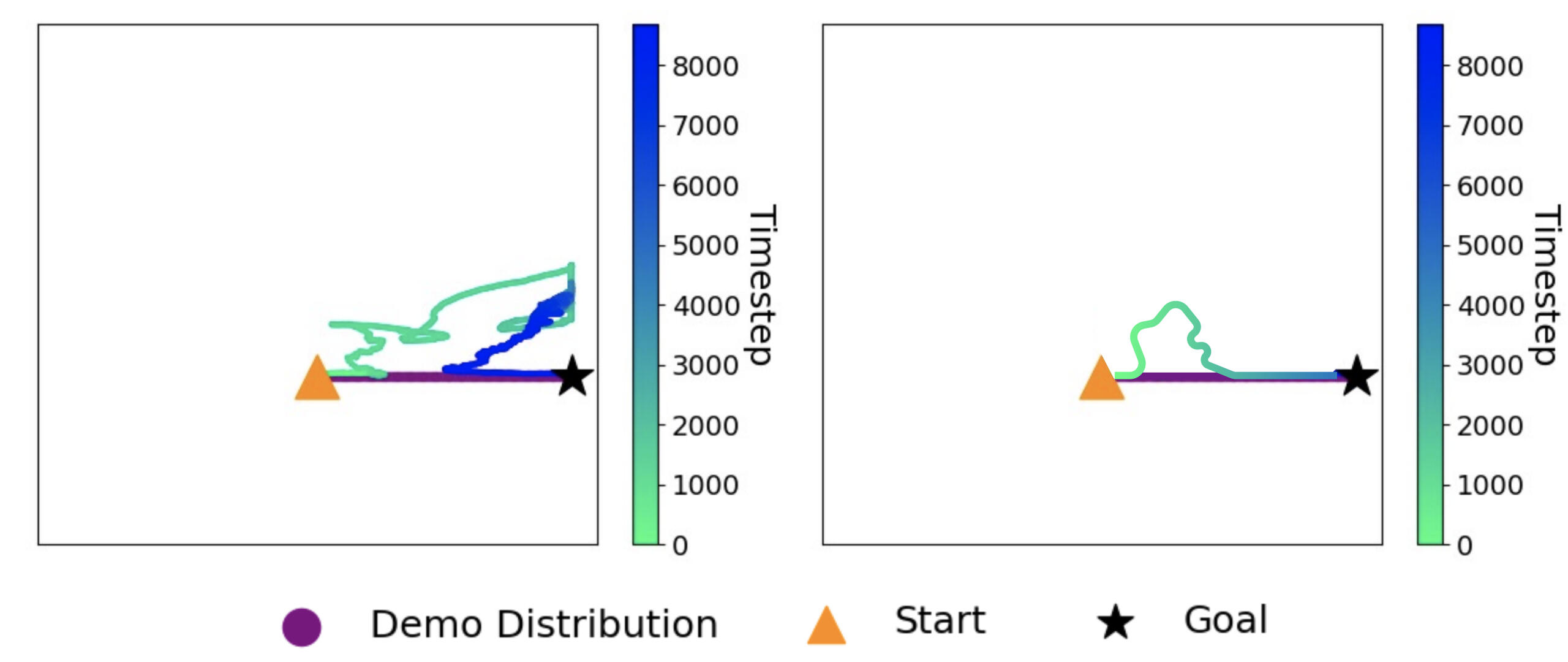
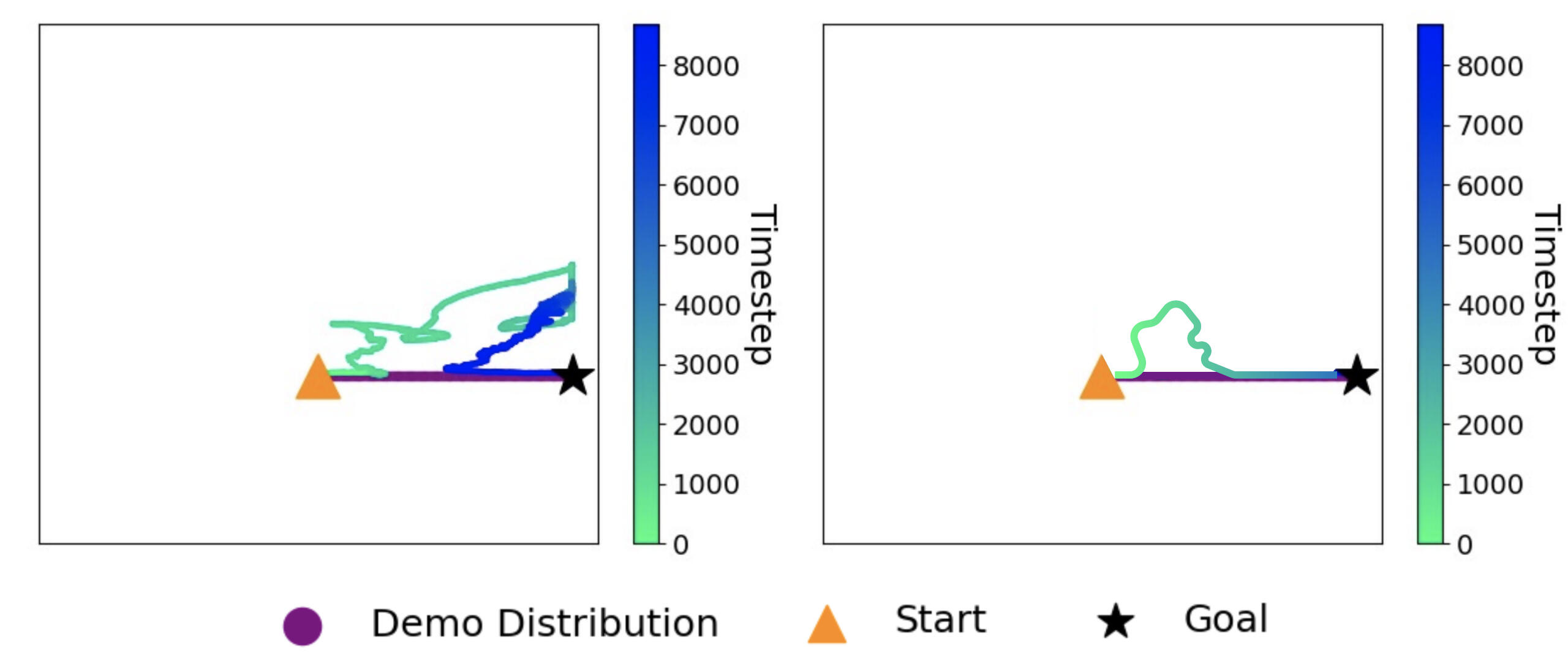
We can also clearly see the incredible effect QWALE has in correcting the behaviour policy back on-distribution in the figure below. The left graph demonstrates what happens to an agent when deployed into a SLRL scenario with novel obstacles without QWALE and the right, with QWALE. The purple line represents the originally learned behaviour policy distribution. Clearly, QWALE has a significant correcting effect! Allowing the agent to get back on-distribution and achieve its original goal despite becoming perturbed by novel obstacles along the way.
This is great. But, perhaps there's still room for improvement! This (if you're still with me!) is what I'd like to explore in the next chapter. I will preface the following by stating that, at this moment in time the ideas presented below are purely theoretical. Although I will be exploring them all more thoroughly and experimentally over the coming months, they may (and likely will) be subject to change or adjustment. Nevertheless, let us continue and explore how we might take inspiration from Prof. Feldman Barrett's theory of Constructed Emotion to introduce "affect-inspired" enhancements to QWALE, potentially making it even better!
Affect-Inspired Enhancements to QWALE
Let's begin by reflecting more broadly on what patterns we observe when applying QWALE in SLRL scenarios. For the case of Rex, upon reaching some novel obstacle (like debris), we witness a drift in behaviour policy distribution away from what was acquired during training. This is Rex adapting to its environment and "overcoming" the novel obstacle. QWALE then acts to realign Rex's adapted behaviour policy back to its original distribution. In effect, we therefore witness a sort of "push" and "pull" force away from and back towards the originally learned behaviour policy distribution. This "push" and "pull" effect is represented quite nicely by the rightmost box in the above figure. To be clear, the push equals an adaptation around the novel obstacle, and the pull, a realignment towards the original behaviour policy.In theory, if we could introduce additional reward signals to "boost" the speed of both divergence and realignment, we might be able to improve the effectiveness of our agent's autonomous adaptability in SLRL scenarios.So...the question is, how do we produce such additional signals?In Prof. Feldman Barrett's Theory of Constructed Emotion she argues that emotions are not innate, discrete entities that we feel as a reaction to the world around us but instead, an active way in which we construct our experiences based on interoception and categorisation. Emotions guide our attention and shape our perception of the world, influencing our behaviour in significant ways. They're a tool with which we appraise our surroundings using past experiences and concepts to make predictions about what’s happening and generate appropriate emotional responses before we've fully registered its reality.For instance, imagine you're walking in a dark alley at night and you hear a sudden noise. If your brain predicts that the noise is a threat based on past experiences and the current context, you might feel fear. However, if you’re in the same alley during the day and hear a similar noise, your brain might predict it as harmless, leading to a feeling of curiosity instead. In both scenarios, the emotion you experience is not a direct reaction to the noise itself but a construction based on your brain’s predictions, shaped by your past experiences and the context.Cool, so what on earth does this have to do with QWALE, and search and rescue robots?Well, it demonstrates that affect can be thought of as a tool through which we appraise our surroundings, guide attention and select behaviours. So, whilst human emotion is an incredibly complex phenomena, we might be able to construct novel reward signals inspired by how we use affect to appraise our environments. Perhaps, as a first step, we could introduce a way of detecting the severity of a novel obstacle based on the potential harm it could cause Rex, and in response boost the speed of adaptation (the push), and subsequent realignment of behaviour (the pull). For instance, we would want Rex to adapt its behaviour quicker in response to a fire obstacle than a debris obstacle because it would be less likely to recover from the harms of walking into a fire. You can adjust this example in whatever way seems reasonable in SLRL scenarios, but the point remains.In a study investigating the effect of stress and predation on pain perception in robots, Prof. Cañamero and Prof. l’Haridon attached infrared sensors onto the body of a "simple" robot to function as "nociceptors" (damage receptors). The robot's goal was to maintain ideal levels of internal variables like energy and temperature while evading predators (other robots) in its environment that, upon detection, would attempt to crash into the "prey" robot and cause "damage." Deviations from the ideal levels of internal variables created error signals that influenced the prey robot's motivations (hunger, cold, and danger avoidance) in varying proportions. In turn, actions such as "seek resources", "explore environment", or "avoid obstacles" were triggered automatically based on which was measured to be most urgent to maintain optimal levels of internal variables.The choice between these behaviours was also influenced by the robot's "perception" of "pain," primarily caused by damage (strikes) to its nociceptors (infrared sensors). Additionally, they introduced a pain-modulator, "cortisol" which acted to increase the salience of pain perception by boosting the signal caused by damage. Cortisol levels would increase in response to higher environmental stress caused by a greater presence of predators.By introducing "pain perception" and modulating it with "cortisol" in this way, the robot was able to prioritise behaviours that minimise discomfort, evade predators, and acquire resources more efficiently while maintaining greater stability of internal variables. The robot also began exhibiting interesting emergent "fight or flight" behaviours. In high-threat situations, it would sometimes engage in "fight" responses, such as "ramming" predators off of areas that provided access to resources. It also exhibited more sophisticated evasion manoeuvres when being chased by predators. Whilst it is clear that descriptors such as "pain perception" and "cortisol modulation" are more illustrative than scientifically accurate, they help explain the mechanisms at play and the inspiration drawn from affective modes of environmental appraisal.So, considering all the concepts explored above, how might we introduce "affect-inspired" enhancements to Rex?Well, perhaps we could introduce "pain" and "pleasure" feedback signals to boost the "push" and "pull" signals already present.
Pain = Damage * PainModulatorPleasure = Success * PleasureModulator
Of course, it should be acknowledged that these descriptors serve as more "illustrative" labels, to demonstrate the root of inspiration, rather than to signify an accurate replication of these phenomena. Nonetheless, by integrating sufficiently suitable sensory mechanisms into Rex's repertoire, we could potentially heighten its adaptive behaviour through these additional affect channels and improve its appraisal of environmental dangers.How would this work in practice?To begin we could focus on detecting novel obstacles most harmful to Rex by equipping it with various sensors to detect threats earlier. It's important to note that these sensors will not feed additional data directly into the behaviour policy network itself. Such an increase in information can produce too much "noise" for the policy network (see this explanation) and increase the overall load placed on the processing systems. Instead these sensors would act via the two "affect" channels (Pain and Pleasure) to produce clear and clean additional reward or error signals. Warning Rex, alongside any data it might already be processing through its RGB camera, of possible, and particularly threatening novel obstacles.Let’s take the example of a fire hazard.If Rex was equipped with heat sensors and approached a fire, the heat sensors would warn of the potential harm of this novel obstacle (by detecting temperature changes) much earlier than Rex's RGB image data would. As a result, the heat sensors would begin producing an error signal through the Damage variable of the Pain affect channel, forcing Rex's behaviour policy to move off-distribution earlier than it otherwise would have. This signal would also act to amplify the normal "push" signal being generated directly by Rex’s behaviour policy from the RGB images too, ultimately encouraging a more rapid suppression of previously learned behaviours that might cause it to take harmful actions such as walking into the fire.As Rex’s behaviour policy begins to diverge, Rex might continue to approach the fire for a short while. However, as the heat sensors detect higher temperatures the Damage variable would increase proportionally and thus, so would the Pain error signal. This would cause Rex's behaviour policy to move further off-distribution by encouraging it to increase its exploration of alternative actions.Eventually, the discriminator network (don't forget about that guy!) will begin to notice a divergence from the original behaviour policy and produce its own error signal in response to encourage Rex back on-distribution. If we observe such a "battle of error signals" without noticing a drop in temperature, we know that Rex's behaviour hasn't adapted effectively yet to move it sufficiently away from harm.In this case we can induce a short burst of the PainModulator variable to temporarily boost the effect of the Damage variable and ultimately Pain error signal, amplifying the selection of rapid adaptive behaviour whilst temporarily suppressing any early corrective behaviour caused by the discriminator network.We can continue to modulate the Pain signal proportionally to how our heat sensors detect the proximity of the fire. As temperature detected reduces, Damage will too and thus the error signal produced by the discriminator network now takes charge. When we notice such discrepancy between the Damage signal from the heat sensors and error signal from the discriminator network we can begin to taper off the PainModulator too.Additionally, we can now begin to trigger reward signals from the Pleasure "affect" channel, by releasing a Success signal in response to registering a particular declining trend after a spike in Pain. We'd use Pleasure as a reward signal that increases in proportion to discriminator network error decrease, "boosting" the realignment of Rex's behaviour and thus amplifying the “pull” effect back towards the original policy distribution.When the discriminator network’s error signal begins to minimise (and Rex's behaviour stabilise) beyond a certain threshold we can induce a temporary PleasureModulator signal to guide the final realignment.In the figure below I've attempted to represent this relationship between Pain, Pleasure and discriminator network error visually.
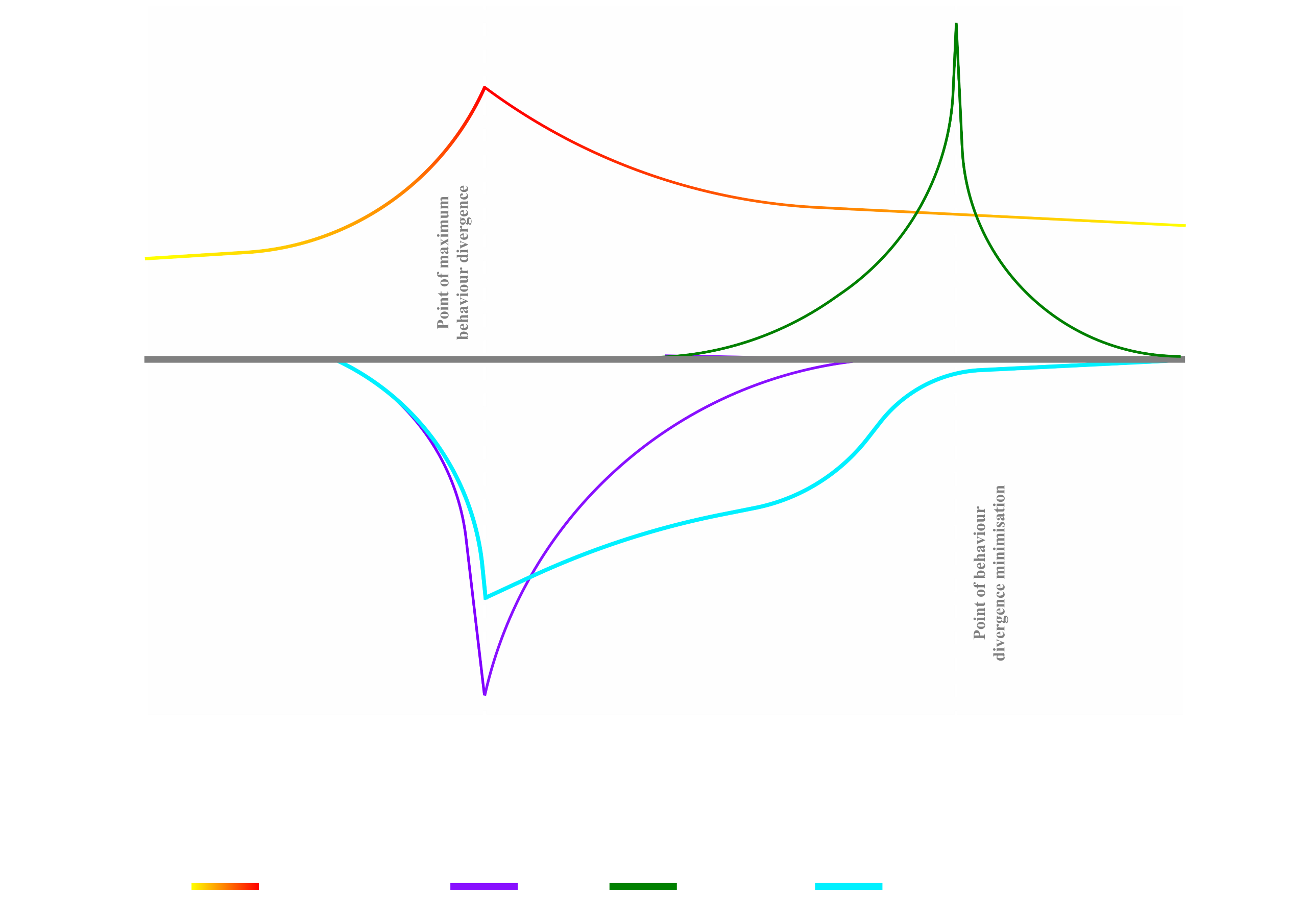
One potential advantage of this system is its ability to incorporate various sensors in a modular fashion in order to address the wide variety of potential hazards Rex could encounter.For instance, we could enhance the detection of falling debris with motion sensors, identify uneven or broken surfaces with depth sensors, monitor the presence of hazardous or explosive gases with chemical sensors, and so on. Each sensor, in turn, acting through the same additional error and reward signals (Pain and Pleasure) that the heat sensor did in the example above.Of course, as previously mentioned, novel environments are inherently unpredictable, but the addition of such sensory inputs effectively captures a good variety of possible novel obstacles.It is also important that, with the addition of new sensors, we do not "overwhelm" the system and create too much "noise" for the behaviour policy network to process. Although, with each sensor acting through the same two modulated affect signals, we create a funnel to de-noise competing sensory inputs and more directly enhance the current adaptive ("push") and re-alignment ("pull") behaviour of an agent like Rex for a wide variety of circumstances.In essence, this system might be an effective manner through which we can equip (and process) autonomous agents with modular "affect-based" sensory powers, facilitating more rapid and efficient adaptation and re-alignment to original policy distributions in SLRL environments.Ultimately, moving QWALE more towards the trend line depicted in the right box of the figure below from the one on the left which depicts QWALE's current effect (right box created for illustrative purposes only).
Closing Thoughts
In this article we explored the various misalignment issues that can arise from sparse reward SLRL scenarios with novel obstacles, such as the deployment of autonomous robots into search and rescue environments. It is clear that addressing such misalignment issues holds significant value. When deploying autonomous agents like Rex into unpredictable, high-stakes environments, the cost of failure can be significant.As we have demonstrated, novel obstacles can result in off-distribution behaviour that compromises the agent's ability to achieve its goals. However, the effective approach of the QWALE algorithm is a promising pathway to mitigate misalignment. It is also possible that, by incorporating affect-based mechanisms which take inspiration from theories such as Prof. Feldman Barrett's Constructed Emotion, we might be able to enhance QWALE further—developing a more dynamic and responsive system that leverages additional sensory inputs to both detect and correct adaptive behaviours for novel obstacles earlier and more efficiently, especially those that might cause our agent significant harm!While these ideas remain theoretical at this stage, their potential implications for AI safety are worth noting. Enhancing the ability of autonomous agents to handle unforeseen challenges not only benefits specific applications like search and rescue but also contributes to the broader goal of developing safer, more predictable, and aligned autonomous robotic systems, such as self-driving cars and specialised surgical robots.
Where Is The Brain Locus of Consciousness?
Estimated Read Time: 15 minutes
Understanding consciousness is an inherently hard problem (Chalmers, 1995) with different approaches across philosophical, psychological and related fields. Generally defined, a conscious being has subjective experiences and is able to reflect upon their own existence (Frith, 2019; Colman, 2015).Amongst psychologists, this understanding is often divided into phenomenal consciousness, what ‘it is like to be you’ and access consciousness, our ability to reason and rationally guide our speech and behaviours (Block, 1995). In neurology, consciousness is often divided into (1) levels of consciousness, ranging from deep unconscious states (e.g. comas) to fully alert wakefulness, and (2) contents of consciousness, the information one is aware of at any moment in time (Eysenck & Keane, 2015).Locating the brain locus of consciousness (BLoC), which I will define as a singular region of the brain where consciousness originates, is a substantial challenge, but nonetheless, an important pursuit. Understanding this could help focus research within medical, technological, and ethical practices, potentially transforming approaches to mental health disorders, artificial intelligence, and neuroethics.Empirical techniques, including visual, attention/memory, verbal, auditory, and sensorimotor tests, probe different aspects of consciousness and have led to the discovery of various neural correlates, including the frontoparietal network, dorsolateral prefrontal cortex and posterior cortical hot zones (Yaron, et al., 2022). Such empirical observations have given rise to various explanatory theories, including Global Neuronal Workspace Theory (GNWT), Recurrent Processing Theory (RPT), and Integrated Information Theory (IIT). These theories suggest that consciousness emerges from coordinated perceptual information processing across a distributed network of cortical and subcortical brain regions, rather than from a BLoC (Liaw & Augustine, 2023).However, one might also propose that, since our experience of consciousness occurs as a bound and coherent perceptual signal of sensory information, the empirically observed coordinated activation of brain regions across a distributed network must give rise to consciousness via some neural integration mechanism binding such information into a single signal of perception, i.e. a BLoC (Crick & Koch, 2005).In this article I will briefly outline the empirical data and resultant distributed network theories of consciousness, before focusing directly on the question in hand and proposing the parabrachial nuclei of the pons, under the Free Energy Principle Theory of consciousness, as the strongest BLoC candidate (Solms, 2019).
An Overview of Distributed Network Consciousness Research
This section offers an overview of the three most popular distributed theories of consciousness (DToCs) (Yaron et al., 2022) and the empirical observations which underlie them. Ultimately, I aim to show their inadequacy and motivate space to explore theories in favour of the existence of a BLoC.Global Neuronal Workspace TheoryGNWT is an extension of Global Workspace Theory (Baars, 2005) and proposes that conscious cognition emerges when information, processed in various subcortical structures, gains access to the global neuronal workspace of the frontoparietal network (Dehaene & Changeux, 2004).Recurrent Processing TheoryRPT proposes that consciousness emerges from feedback loops between higher- and lower-level brain areas. Feedforward (unidirectional) processing handles information in fragments. This only turns into coherent and conscious information when recurrent processing occurs. RPT functions via plastic changes to synaptic connections, a process mediated by N-methyl-D-aspartate-receptor-dependent feedback activations (Lamme, 2010).Integrated Information TheoryIIT suggests consciousness arises from the brain’s ability to combine information from different domains of neural processing in a unique and indivisible way. This integration is quantified by the brain’s irreducible intrinsic cause-effect power, measured as its Φ value (Tononi, 2004). Φ is thought to peak in the posterior cortical hot zone (Yaron et al., 2022).Inadequacies in DToCsIt is evident that each theory presents unique translations of empirical observations, offering different neural modalities through which consciousness emerges. However, it is also the case that they align on the process through which these modalities cause consciousness to emerge – the coordination of perceptual stimuli across distributed networks of cortical and subcortical regions. Such DToCs are incompatible with the existence of a BLoC as they necessitate all regions working together to produce the phenomenon of consciousness.I will present two major problems with these theories: (i) the empirical evidence supporting these theories originates from research shown to possess confirmation biases, and (ii) consciousness can be shown to exist without the cerebral cortical regions which each theory suggests are crucial for its emergence.In a meta-analysis of n = 412 studies investigating IIT, RPT, and GNWT between 2001 and 2019, Yaron et al. (2022) presented clear evidence of systematic and consistent confirmation biases. Examined together, fMRI data across studies demonstrated that conscious perception results in activation across almost all regions of the brain. Yet, when fMRI data is categorised by theory-type, distinct patterns of brain activation emerge which appear to only support the theory that study aimed to empirically investigate (Yaron et al., 2022).This suggests researchers might be neglecting or explaining away data that is incompatible with the predictions of their theory, or that each theory only explains a specific aspect of consciousness, with unique modalities of testing that cannot access other aspects. The latter conclusion is perhaps supported by the fact that, of all the experiments investigated, 86% focused on probing consciousness via its content using visual stimuli only, thus neglecting both the level of consciousness, and other important sensory modalities like attention/memory, auditory and sensorimotor (Yaron et al., 2022). This is a problematic observation and draws into question the efficacy of empirical observations used to support DToCs.It is also the case that IIT, RPT, and GNWT place great significance on the role of the cerebral cortex in consciousness, specifically the prefrontal cortex, N-methyl-D-aspartate receptors, and posterior cortical hot zone regions. It is presumably uncontroversial to suggest that any theory weighted upon the functional role of a particular brain region for the production of consciousness is immediately falsifiable if the ablation of such structures does not result in a loss of consciousness.Consciousness has been shown to remain intact in patients with complete destruction to the very brain regions these theories specify as crucial for consciousness (LeDoux & Brown, 2017). Further, children born without any cerebral cortices at all (hydranencephaly) exhibit rich conscious experience (Merker, 2007), and so do decorticate animals (Damasio & Carvalho, 2013). By extension, it is therefore uncontroversial to state that IIT, RPT, and GNWT (as defined in this article) are erroneous—or at the very least, incomplete.
Identifying a BLoC
Despite the potential confirmation bias of each theory’s empirical data, when examined together, brain imaging data from Yaron et al.’s (2022) meta-analysis suggested global neuronal activation likely co-occurs with consciousness. This is intuitive from a psychological perspective, as we know conscious perception comprises the integration of multiple sensory modalities (visual, auditory, and sensorimotor) and sub-modalities (colour, pitch, temperature) dependent on different regions within the brain.However, since it is not entirely clear that consciousness is simply an emergent phenomenon of DToCs, there’s space to propose an alternative perspective—namely, a neural integration mechanism binding cognitive information into a single signal of perception. Or, as phrased by Crick and Koch (2005), a neural ‘conductor’ coordinating the ‘orchestra’ of global brain activation – a BLoC.Crick and Koch (2005) proposed the BLoC could be the claustrum, a thin, irregular sheet of neurons located underneath the neocortex that sends and receives signals to almost all regions of the cortex. However, this proposition has since been shown implausible since research has demonstrated claustrum lesions do not always result in loss of consciousness (Chau et al., 2015). Further, upon their surgical removal, patients have been observed to retain full long-term sensorimotor and cognitive functioning (Duffau et al., 2007). Nonetheless, the idea of a neural conductor remains a plausible assertion.A recent paper by Solms (2019) suggests the parabrachial nuclei of the pons (PNP), located in the brainstem core, could be a strong alternative candidate for the BLoC. The likely involvement of the brainstem in consciousness was first observed via lesion studies within a brain region known as the extended reticulo-thalamic activating system (ERTAS). ERTAS lesions resulted in the total eradication of consciousness—a phenomenon first observed via cats (Moruzzi & Magoun, 1949) and subsequently replicated in humans (Penfield & Jasper, 1954). More recent studies have refined this locale further to the PNP, where small lesions resulted in the inducing of comatose states (Golaszewski, 2016).Solms (2019) attempts to reconcile these empirical observations under the Free Energy Principle Theory (FEPT) of consciousness. FEPT posits that consciousness emerges from affect (our feelings), defined as responses to internal model prediction errors of external stimuli as we strive to maintain homeostasis. These errors are prioritised by their sensory significance, guiding actions and decisions via differences in affect.From a theoretical perspective, FEPT aligns with Freud’s assertion that affect is intrinsically consciousness (Solms & Nersessian, 1999). Conscious experience requires that there is something it is like to be you (Nagel, 1980). When we reflect on perceptual stimuli more broadly, it is not necessarily the case that there must always be something it is like to see, hear, or learn. For example, in masked stimulus experiments, humans have been shown to learn about and act upon information presented visually without conscious perception (Sid & Stanislas, 2007).However, it is entirely oxymoronic to suggest there is such a thing as feeling (or affect) without there being something it is like to feel. One might argue that all emotions are not necessarily conscious, but this would simply position affect as the conscious experience of emotion (Solms, 2022). In summary, if we wish to identify consciousness, we must be guided by affect, as there exists no way to decouple the two phenomena; one is a foundational aspect of the other.GNWT, IIT, and RPT do not explicitly account for the importance of affect, but the ERTAS, which joins together at the PNP, plays a crucial role in its cognitive emergence. This is supported by research on psychotropic medications which aim to adjust our moods and anxiety. Such studies have been shown to act via neuromodulators within the ERTAS nuclei (Meyer & Quenzer, 2005).Further, returning to the earlier example of hydranencephaly used to invalidate GNWT, IIT, and RPT—children who exhibit conscious behaviour without possessing cerebral cortices notably possess intact brainstems, and further exhibit strong emotions and emotionally motivated behaviour (Merker, 2007).It is likely, therefore, that the PNP is a strong candidate BLoC. Its centrality within the brainstem positions it well as a hub for integrating sensory information and modulating neurophysiological responses to prediction errors. The role of the PNP in autonomic functions and its extensive connections to both higher cortical regions and sensory systems aligns well with FEPT’s emphasis on internal model updating based on the full modalities of sensory input. Further, evidence from psychotropic medicine and lesion studies both suggest the PNP plays a crucial role in processing affect and maintaining a consistent state of consciousness.
Potential Critiques
I will close this article by addressing two strong potential criticisms of FEPT and the PNP.Critique 1 – The PNP Is Necessary but Not Sufficient for Consciousness
Koch (2004) has previously suggested that the brainstem is more likely an enabler, rather than the origin, of consciousness. Likewise, one could propose that the PNP is necessary but not sufficient for the creation of consciousness, as it relies on the perceptual stimuli received via the ERTAS and from neuronal circuits linked to other cortical regions. Consciousness, in this view, cannot arise from the PNP alone. It is therefore not the BLoC, and it is unlikely such a thing exists.Critique 2 – The Hard Problem of Consciousness Remains
Chalmers (1995) famously argues that consciousness cannot be fully explained functionally (i.e., purely physically), as such approaches fundamentally fail to address qualia—the subjective qualities of conscious experience. Locating a BLoC should, in theory, capture all aspects of consciousness, but since this is an impossibility, functional accounts of consciousness like FEPT are inherently incomplete.A ResponseTo Critique 1, one could argue, based on the cases of hydranencephaly discussed earlier, that conscious awareness can primarily arise from brainstem activity, thus supporting the PNP’s candidacy as the BLoC. However, there are clearly additional philosophical dimensions to address. Defining the BLoC as the region of the brain where consciousness originates, the PNP would therefore have to be the first brain region to activate during conscious awakening. This position would not preclude the involvement of other regions, such as the ERTAS, in the sustaining or maintenance of consciousness.Coenen (1998) demonstrated that the mesencephalic reticular formation of the brainstem is the root of activation and arousal for the entire thalamocortical system. This results in an arousing state characterised by a rise in thalamocortical activity and an influx of sensory information to higher brain centres, leading to perception and conscious awareness. Thus, it is plausible to suggest that the brainstem could be the first brain region to activate in conscious awakening. Nonetheless, it is likely that greater empirical evidence is needed to support this claim, and future research should explore it further.To Critique 2, Chalmers (1995) argues that functional explanations of consciousness fail to account for qualia due to the “explanatory gap” between functionalist accounts (such as perception, memory, and language) and the subjective essence of conscious experience. However, FEPT avoids this functionalist trap by focusing on affect. Affect bridges the explanatory gap and sufficiently accounts for the qualia of consciousness because it reflects the intrinsic emotional and subjective qualities that are central to its phenomenological aspects.Affect, as posited by FEPT, is fundamentally about the experience of feelings, which are immediately known and felt by the individual. This approach directly engages with qualia by explaining how affective states are shaped by the brain's predictive coding and error correction mechanisms (Solms, 2022).I acknowledge that there are likely more critiques of the position of FEPT and the PNP as a candidate BLoC, including potential empirical methodological limitations, alternative theories, and the generalisability of such claims across different species and developmental stages. However, it is clear that this is a promising position at present—not beyond useful consideration—and worthy of future empirical and theoretical pursuit.ConclusionLocating the BLoC is a highly technical but valuable endeavour within the realm of psychological and neurological research. This article compels a re-evaluation of classical assumptions toward DToCs such as GNWT, IIT, and RPT due to the questionable nature of the empirical data supporting them, and the existence of cases where consciousness persists in the absence of cerebral cortical regions.Such shortfalls underscore the plausibility of a more centralised mechanism of consciousness—the BLoC—and evidence suggests that this could be located at the PNP within the brainstem core. The PNP integrates and modulates sensory information and neurophysiological responses from the ERTAS and other equivalent neuronal circuits, aligning with the FEPT of consciousness, which highlights the central role of affect.The potential of the PNP as a strong candidate BLoC can be shown to withstand initial critiques, but future research is necessary to substantiate its role in consciousness.